SMS with ChatGPT, offline


Two weeks ago, I experimented with an idea with a few friends
Can people without internet also use ChatGPT?
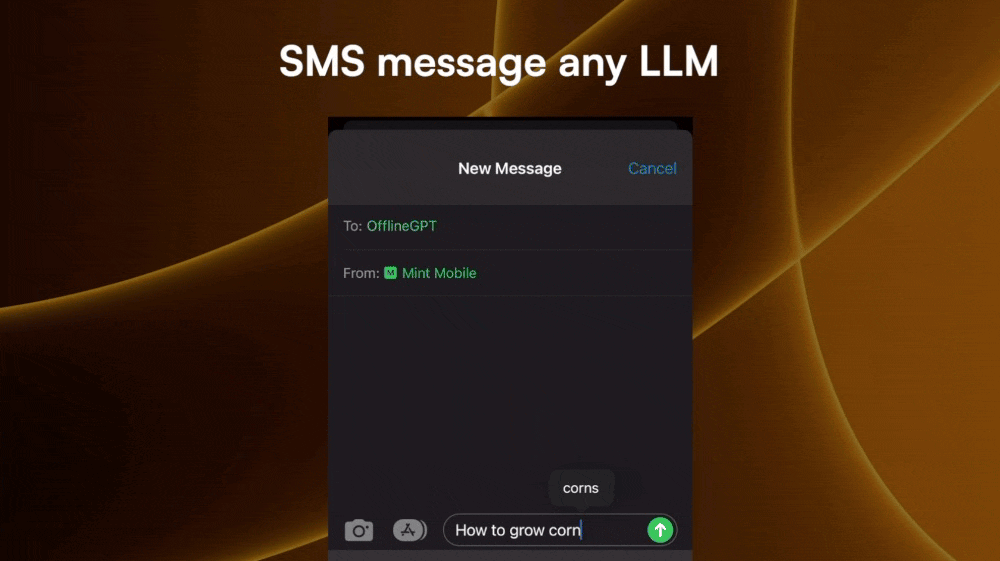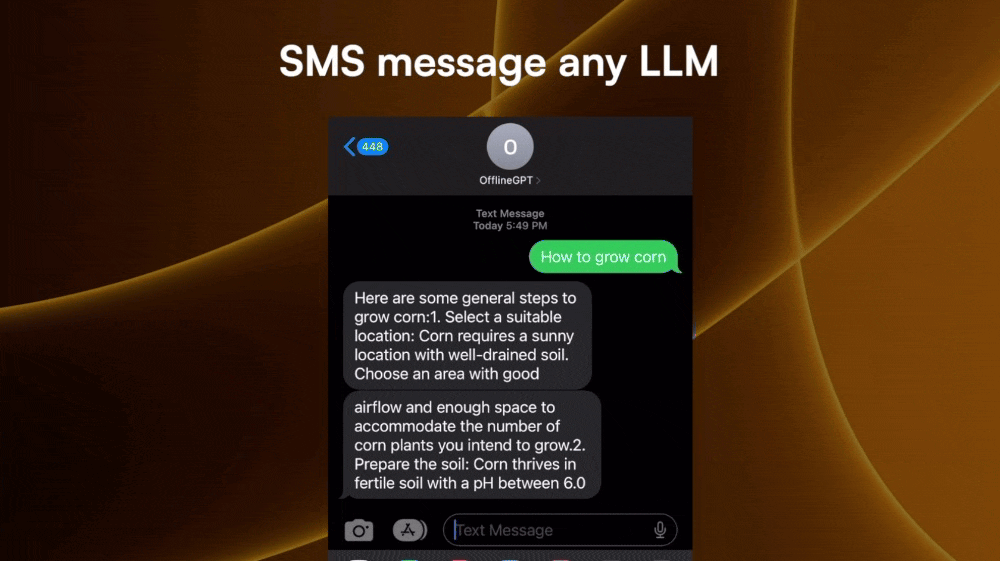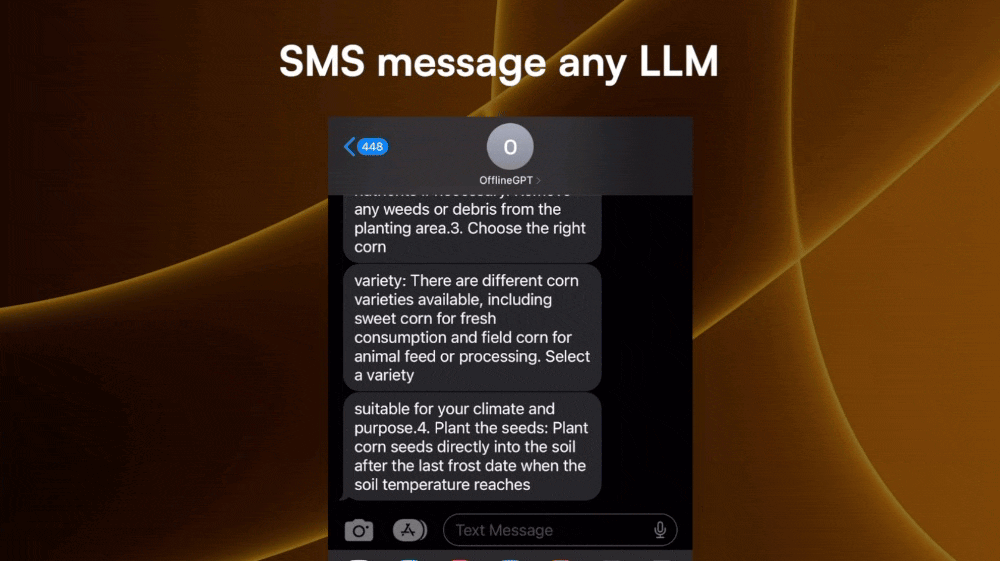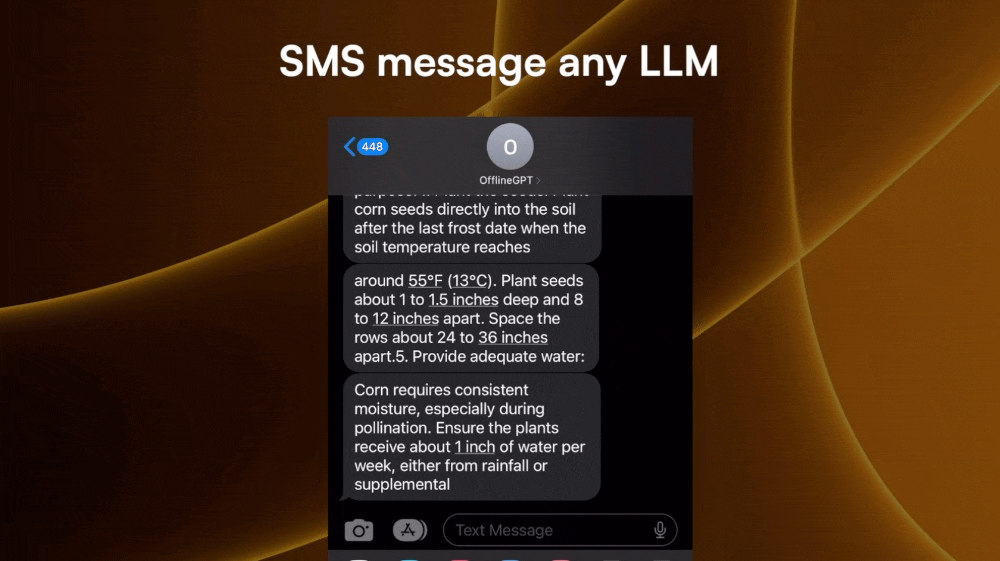
I was talking to a friend that I made in Argentina and they didn’t know that ChatGPT exist. And when I explained what it could do, he was mind-blown, telling me how it will change his life as a student.
So why can’t he use ChatGPT? He does not have internet all the time. He had to go to a nearby cafe to get connected, and the cafe only opens in day time.
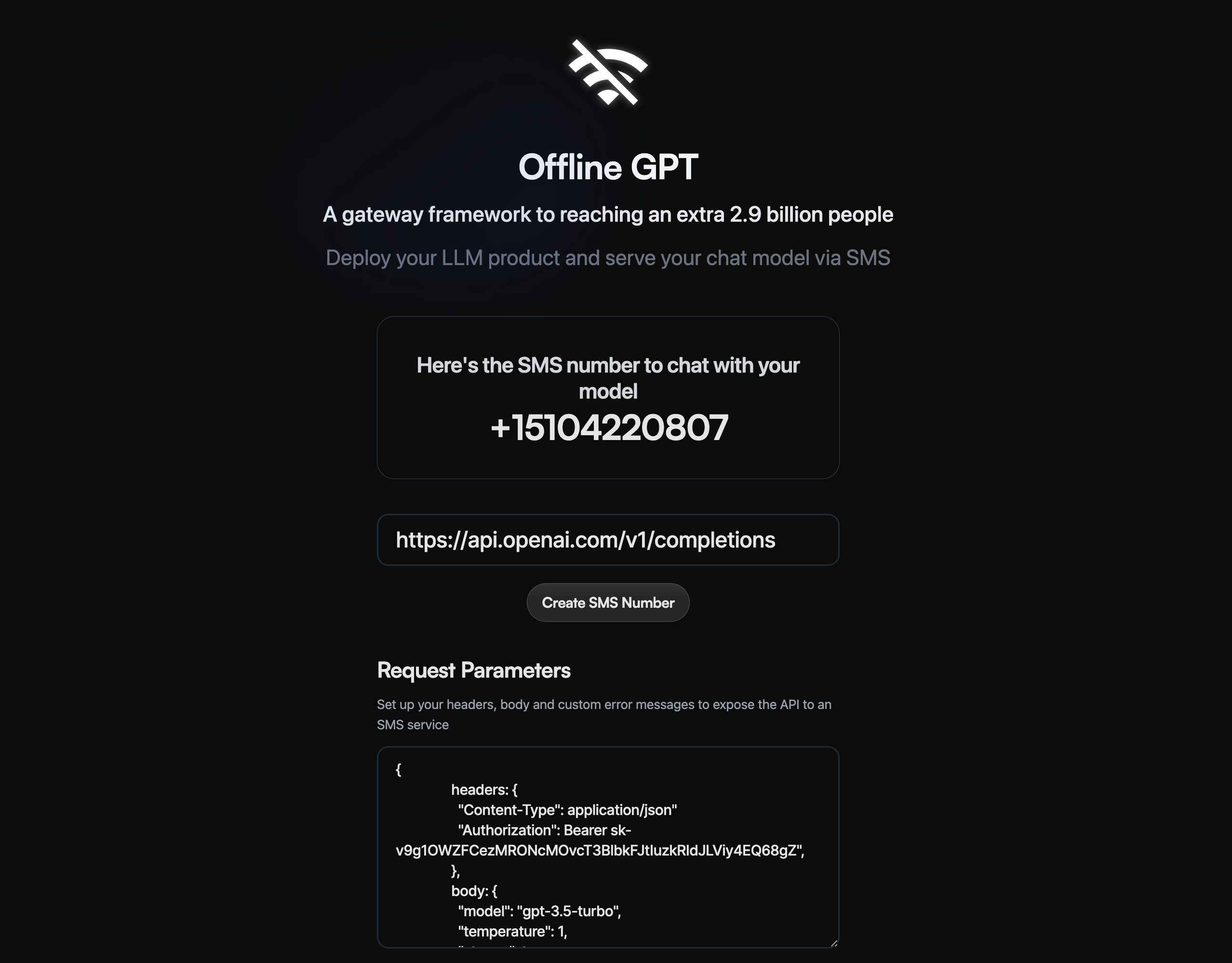
Inspired by his story, I hacked together a solution that gives him a number to text to as if he is chatting on the ChatGPT website.
Why are we putting ChatGPT on SMS?
The most obvious case is to serve the people who do not have internet access. There are 2.9 billion people in the world who still do not have internet access and many more who do not have stable enough internet constantly. Being able to chat with an LLM offline provides massive value for learning and productivity.
A less obvious case is times when the only communication channel is through text messages. We receive messages about online shopping orders, Ubers, flights, and hotels all the time. Wouldn’t it be great to be able to chat about our orders naturally, instead of typing numbers to navigate through menus of options?
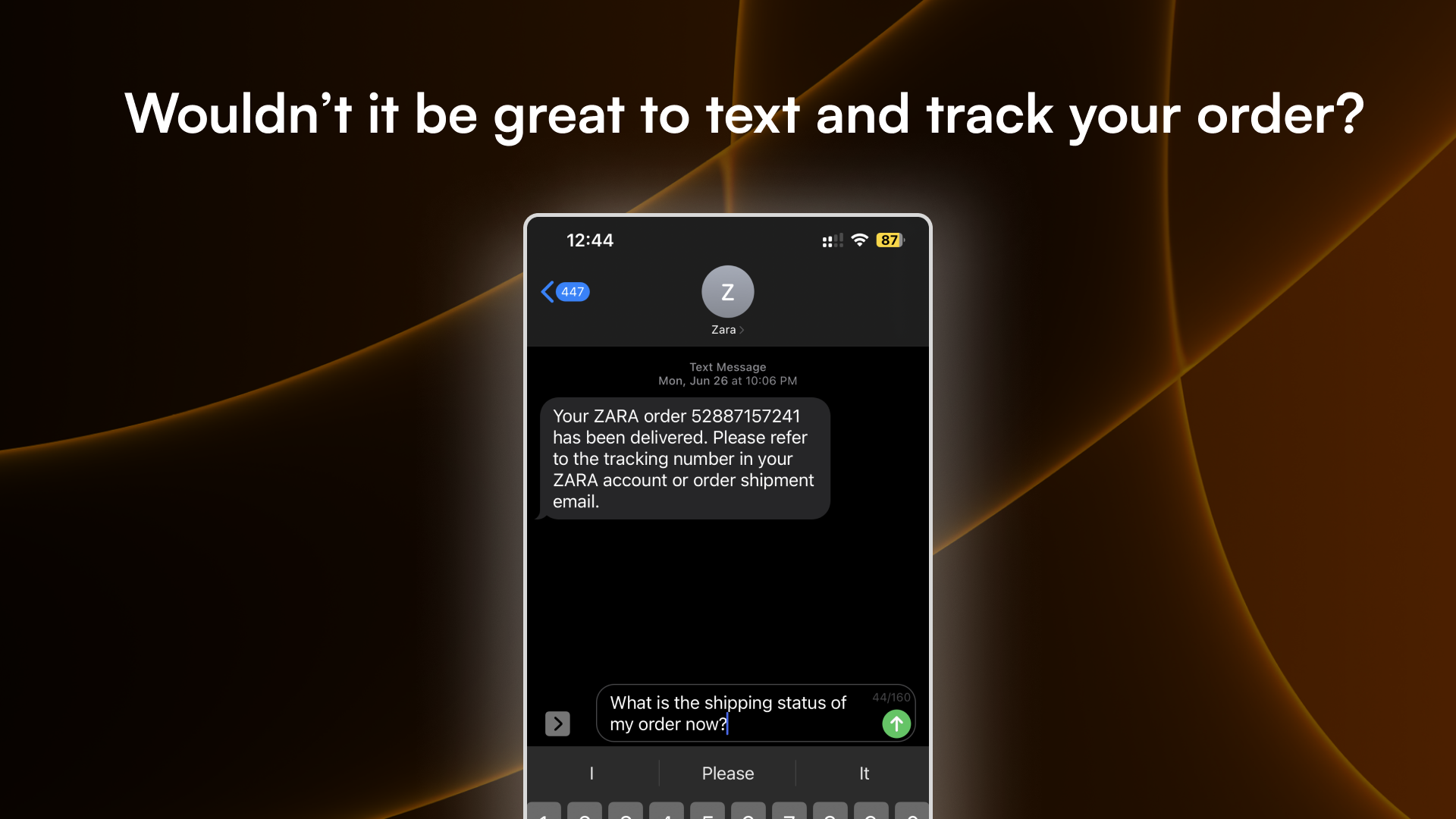
And it's not just ChatGPT…
If we can do ChatGPT, why can’t we do all LLMs?
That’s what we asked ourselves at the beginning. So we built this as a communication middleware for any LLMs to expose to users through SMS as the interface.
Any LLM with an API route can convert its service into an SMS number. Then anyone can text that number to chat with that LLM.
The reasons we choose to become a communication middleware, rather than just a SMS version of ChatGPT are:
Instead of being dependent on ChatGPT, we essentially become a developer infrastructure for all LLM developers who want to expand their client-side interface from just web chat to SMS (and other text services like WhatsApp)
Businesses that only has the phone number of their customers can use this to deploy their LLM chat to their customers. We then empower their customer engagement, customer service, monetization strategies as well
How does it work?
Each LLM service will have a number (or multiple numbers depending on the countries it wants to expose to). All the user needs to do is send messages to the number the same way he/she would chat with an LLM.
In the backend, there are a few modules to convert the LLM chat into an SMS service:
SMS service to receive and send messages to the user, powered by Twilio.
Backend socket that sends prompt and history to any LLM API endpoint and receives responses from it.
Backend processing streams the response as SMS messages, which has a character limit of 160 characters per SMS message.
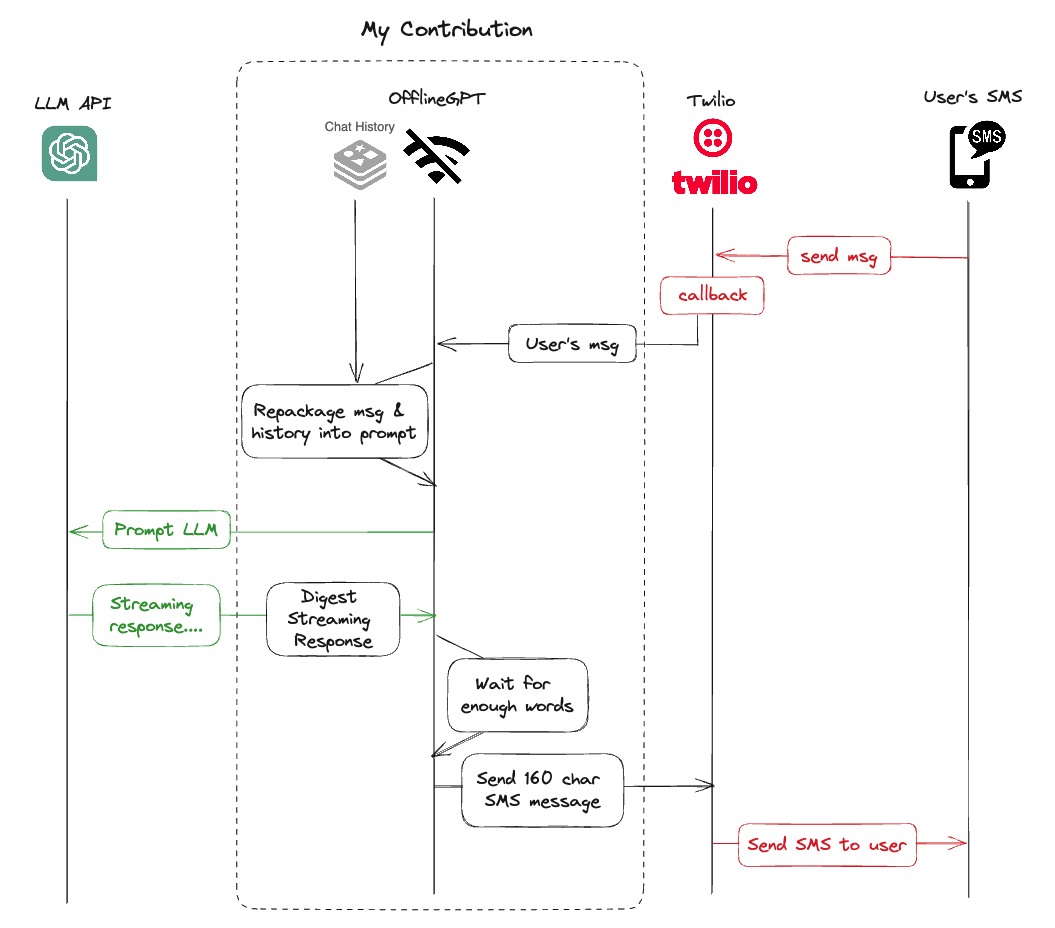
This backend service also needs to support multi-tenancy, where each LLM would have its own SMS number and corresponding backend service. If the LLM is multi-regional, each region would also have its own number and backend service.
Working within constraints
We want to make chatting on SMS as similar to chatting on a website as possible. But we only have SMS as the interface, which is offline and character constrained.
In addition, LLM chats know the context of the conversation. But some LLM’s APIs do not store conversation history. How do we pass that context every time the user text the LLM?
Finally, we want to give the fastest response possible for the user. How do we minimize the prompt-to-first response time?
These are the constraints and challenges that I am in charge of when building this product.
Spitting out responses as fast as possible
How do we give the fastest response possible for the user without them having internet?
In LLM chat apps, we are so used to seeing the response come out word by word as if there’s a person on the other side typing it out. But in SMS, we can’t send one word per message.
Mimicking the streaming response we often take for granted in LLM websites is a two-fold challenge:
How to receive and digest the LLM response as a stream of tokens (aka words)?
How to package it into an SMS message that is within 160 characters?
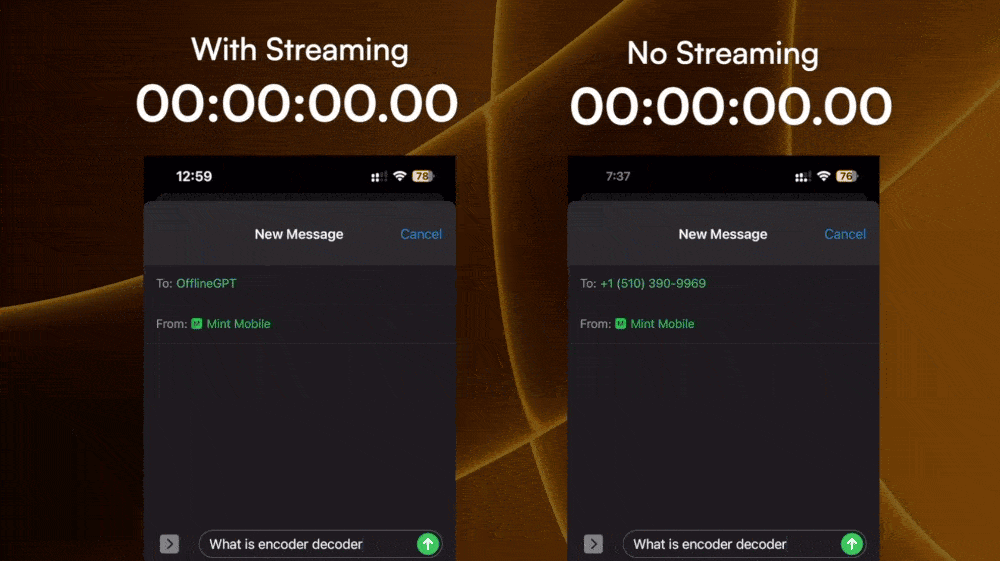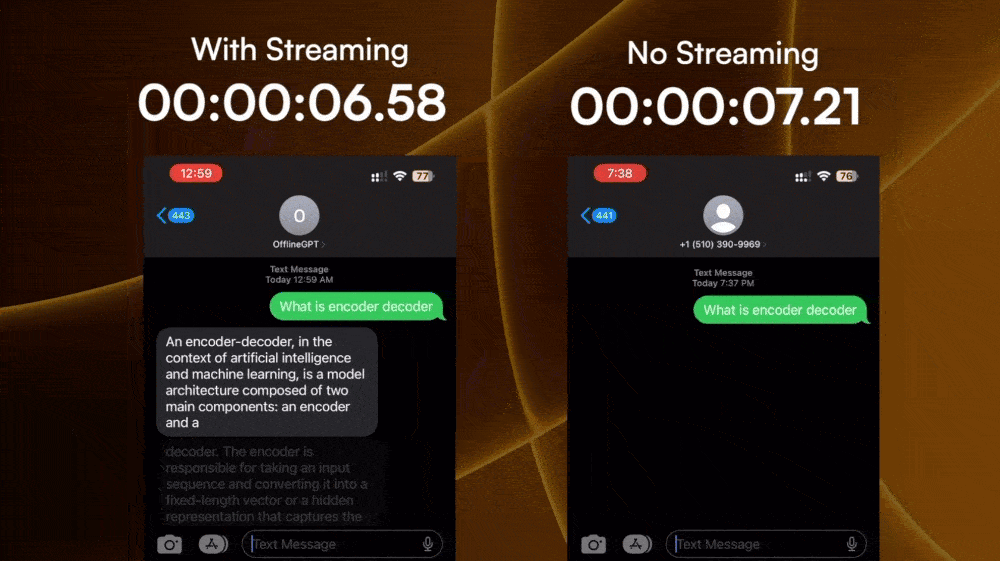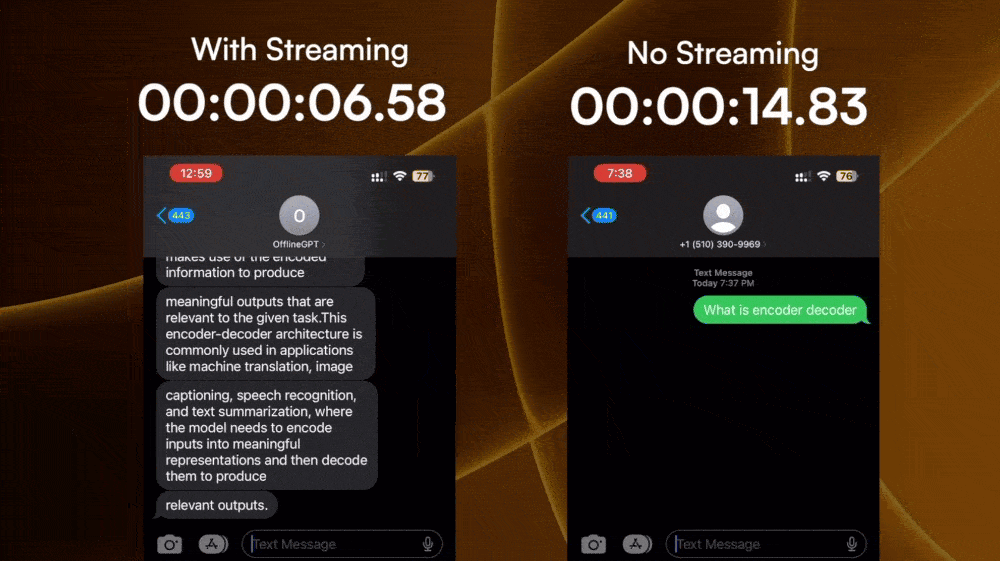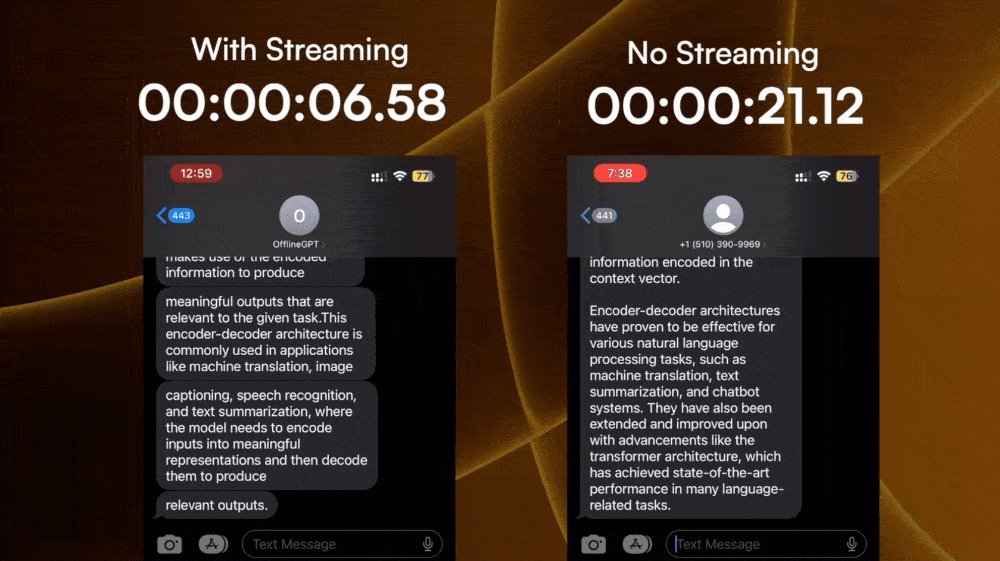
The first challenge seems complex but is actually quite solvable. Some LLM APIs (for example, OpenAI) provide a streamable option so that the response is a ReadableStream
ReadableStreamrepresents a readable stream of byte data, for example, text
All I need to do is ingest the readable stream of data into our backend service, which then allows me to chunk them into messages.
// The OpenAPI ChatCompletion API returns a ReadableStream as a response
// It needs to have a reader that read the stream data supplied from the response
const reader = response.body!.getReader();
reader
.read()
.then(function processText({ done, value }): Promise<void> | undefined {
if (done) {
console.log("stream complete");
res.status(200).send({ body: "steaming done" });
return;
}
// Each token is returned as a UTF-8 encoding,
// Therefore, it needs to be decoded to return as a legible text
const decoded = new TextDecoder().decode(value);
// For OpenAI streamable response, the word that got spit out
// is contained in the data object
const json = decoded.split("data: ")[1];
// Steps to extract the actual word that got spit out
const aiResponse = JSON.parse(json);
const aiResponseText = aiResponse.choices[0].delta.content;
// Repeat the processing step as more data is supplied
// through the ReadableStream into the reader
return reader.read().then(processText);
})
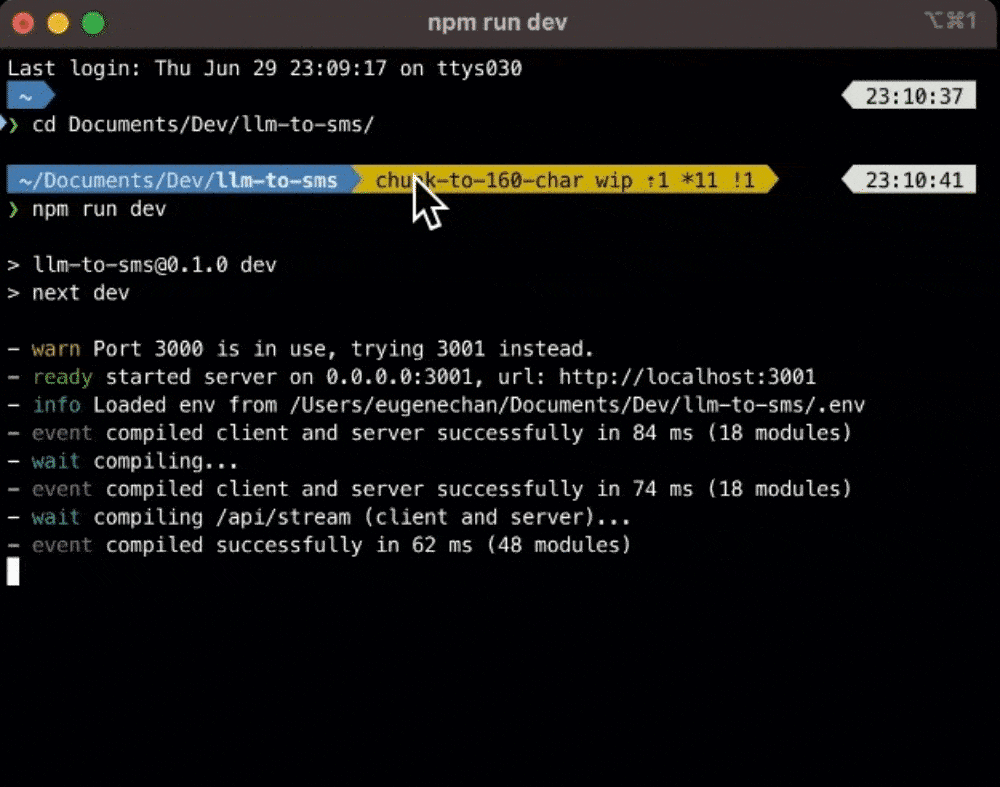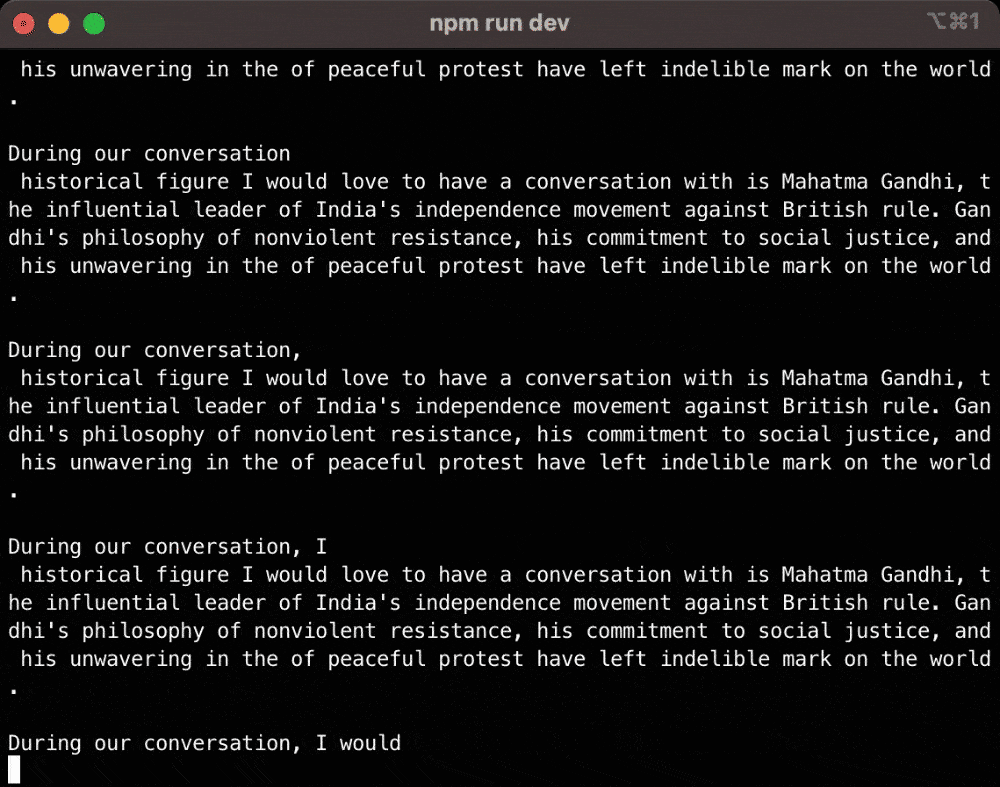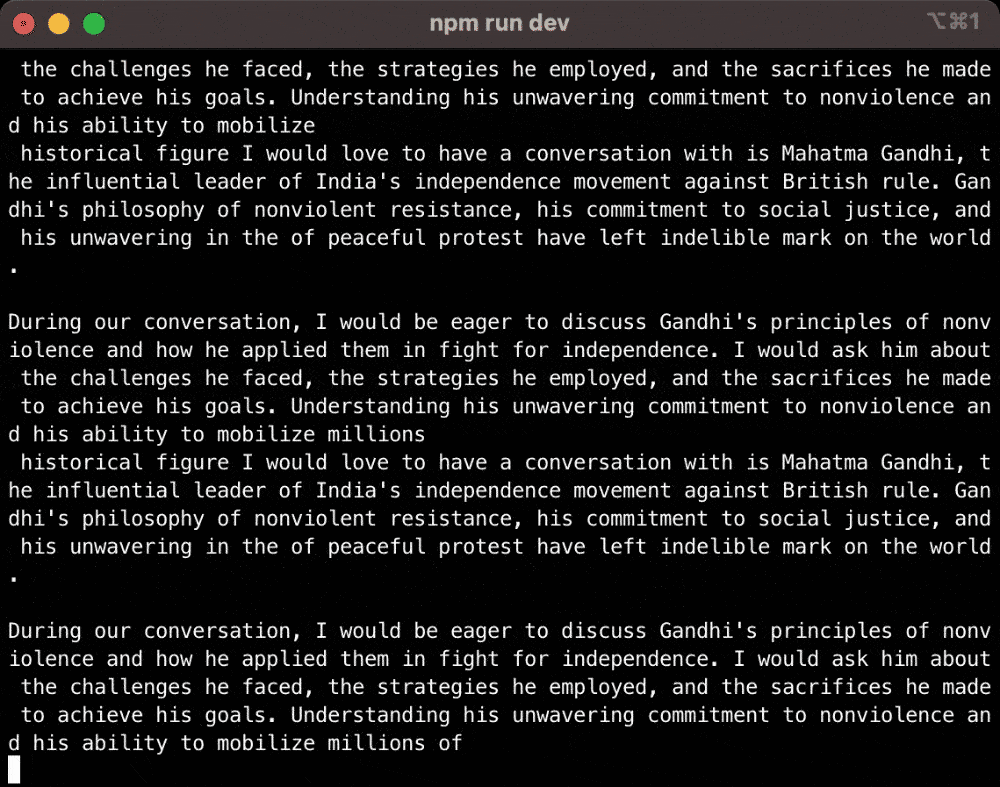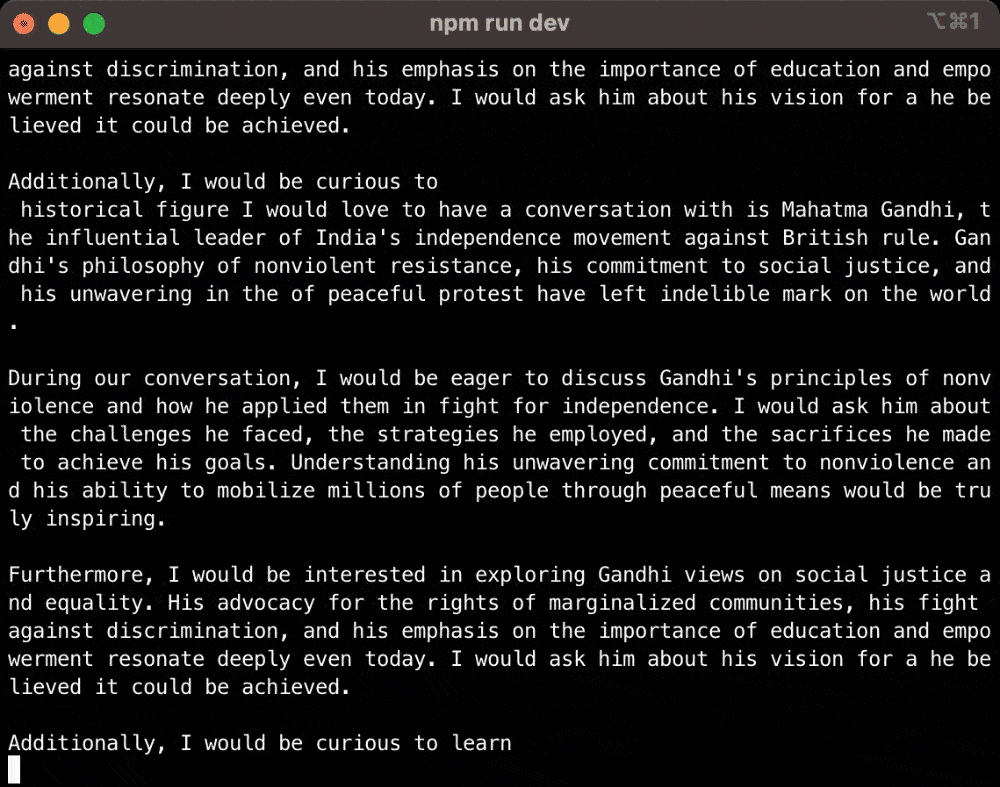
Now that I have the response as each word comes in, I have to package it into 160-character long SMS messages. This challenge seems easy, but took me the longest time to finish. The hard part is how to split the response in a way that feels natural while keeping it within 160 characters.
How to chunk the response so it feels natural, but keep it within 160 characters
I came up with a few rules for chunking:
If the current chunk is less than 140 characters, add the next word to the chunk
If the current chunk is more than 140 characters, end the chunk if the next word is a punctuation (e.g. comma, period); if not, keep adding the next word to the chunk
If the current chuck is more than 160 characters, remove the last word and put that in the next chunk
So instead of chunking randomly, the text message feels like a human is typing
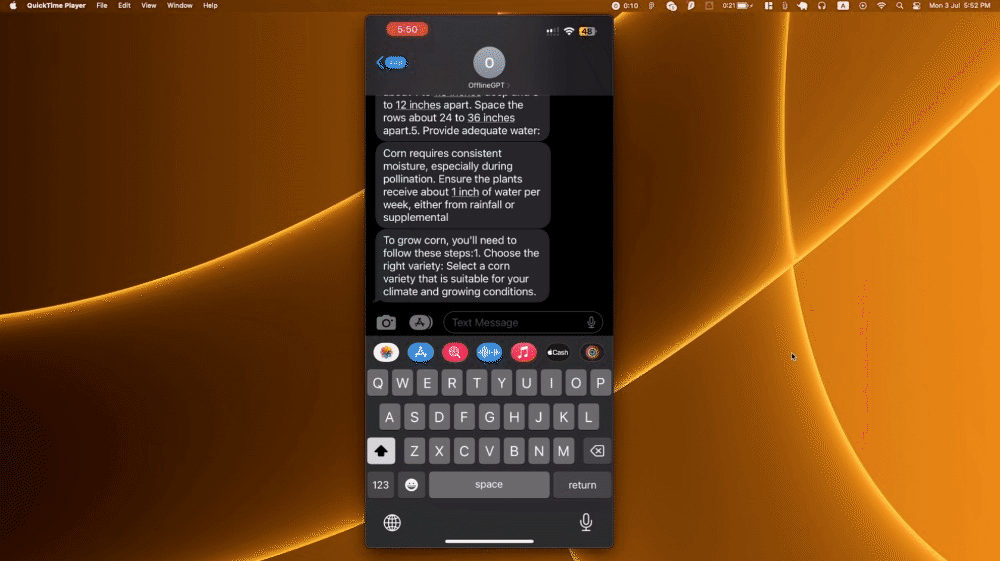
Making the SMS number know the conversation context
Other than being smart, what differentiates an LLM chat from traditional chat bots is that we can ask follow-up questions to it. It understands the conversation context that we are having.
Some LLM API service saves the chat history of the user on their own servers. But most of them don’t, such as OpenAI’s API. They rely on the developer or user to provide the chat history.
But SMS does not have the same benefits as the web. It does not allow authentication, hence you cannot store the chat history by the user. It does not have any on-device storage that we can fetch. It cannot fetch data from other sources and include it in the text.
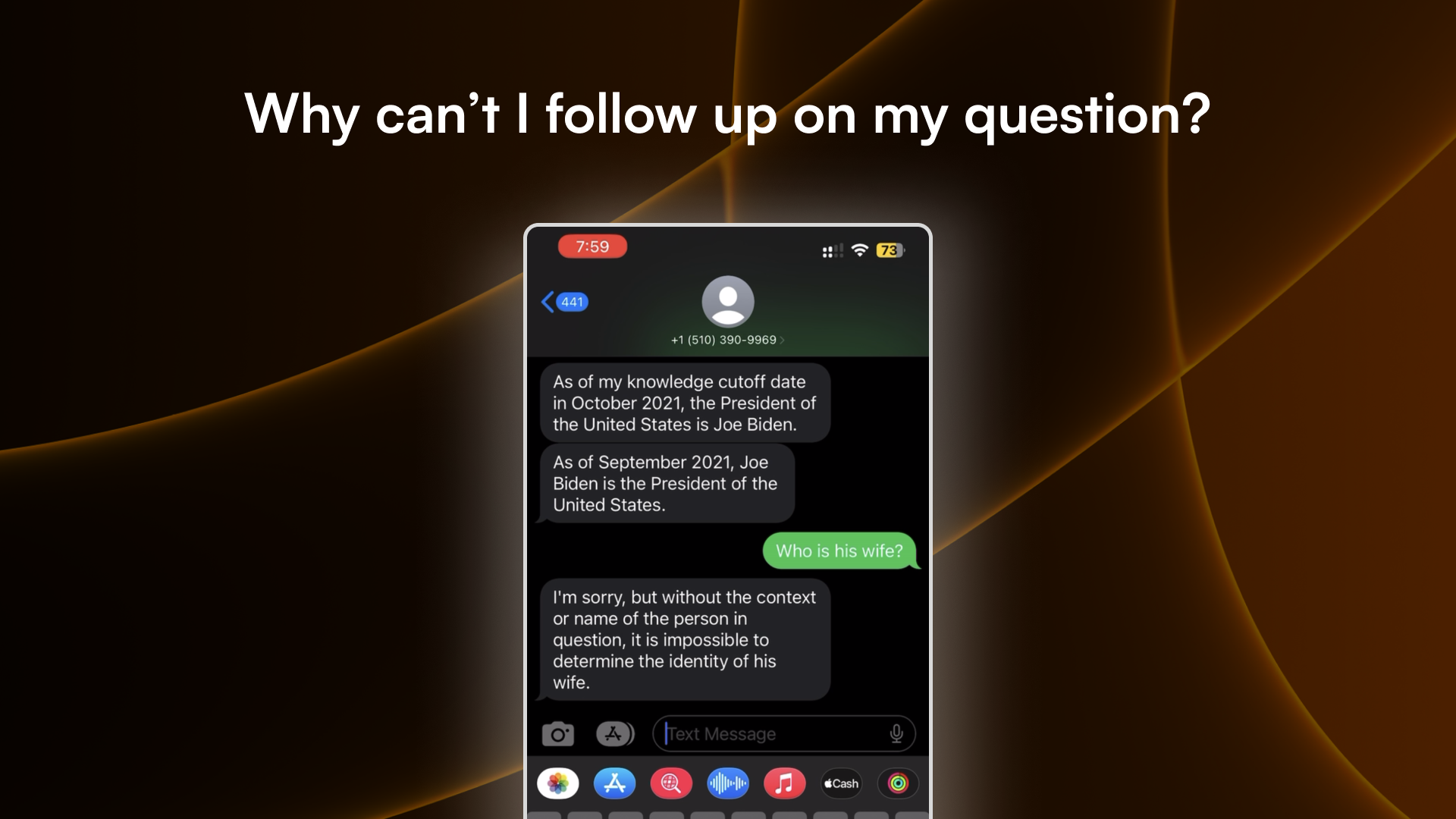
We also do not want the user to deliberately “prompt engineer” their text to include the context of the ongoing chat. So how can we make the LLM context-aware, even in the SMS format?
I tried two approaches…
1. Parse the entire text history of the user as the context
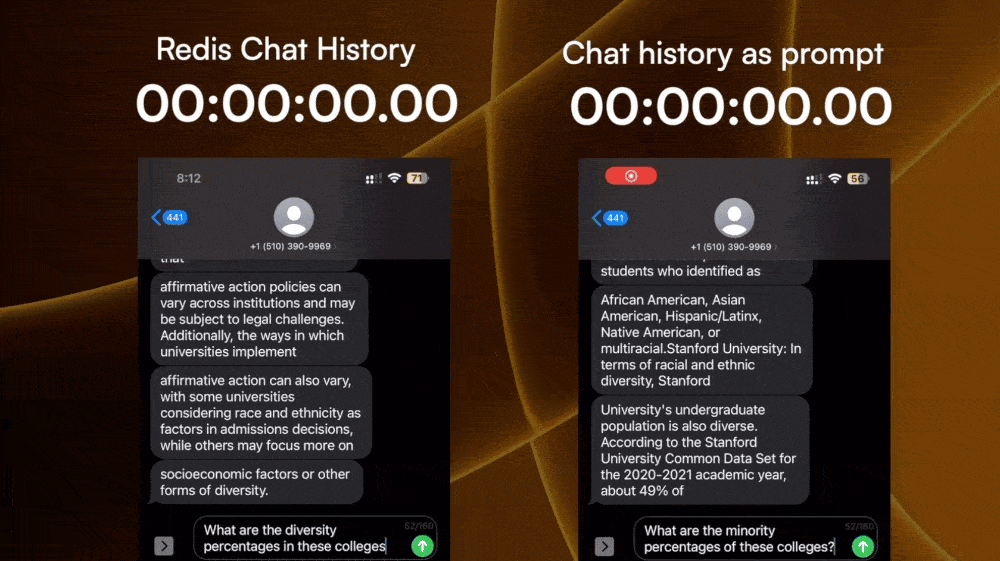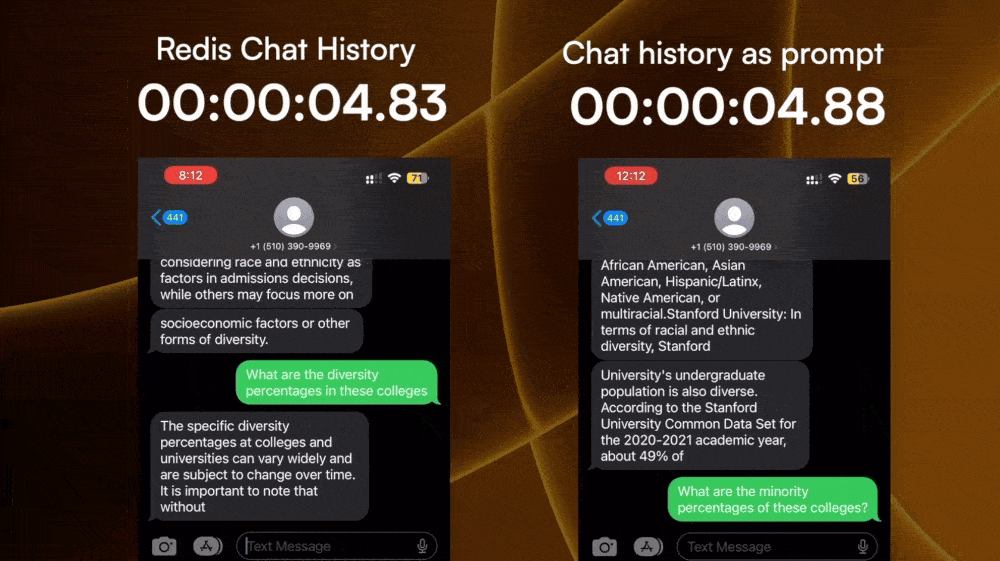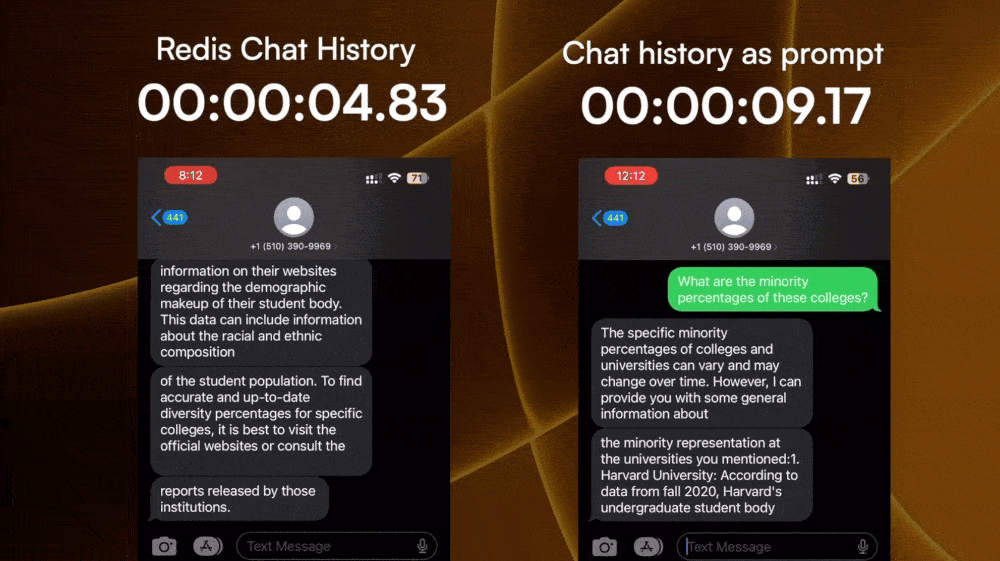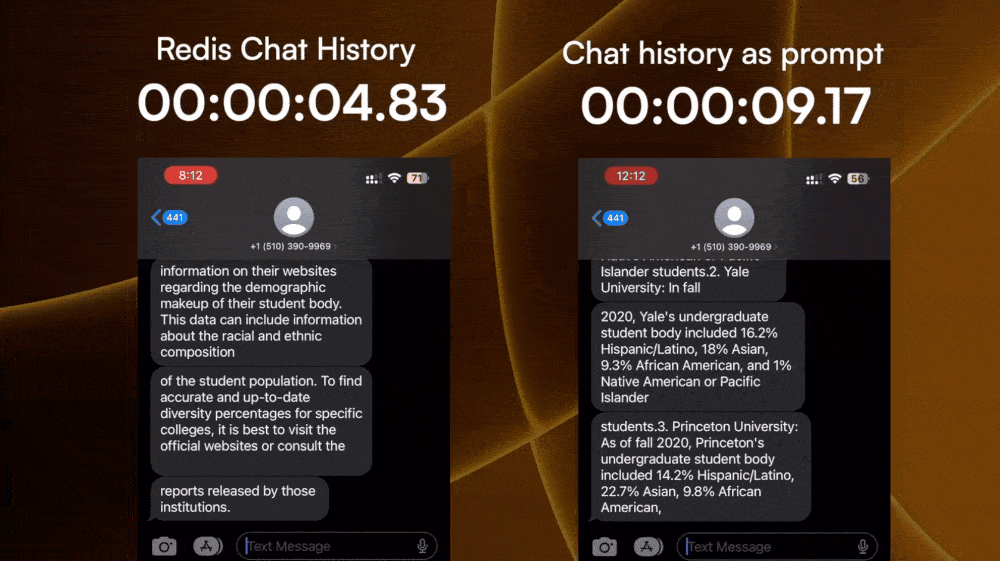
Turns out, Twilio has the ability to pull the chat history of a sender. So we can pull the entire chat history between the user and an LLM SMS number, and inject it into the next chat prompt through some basic prompt engineering.
However, every extra token added to the prompt would increase the complexity, hence processing time before the LLM can spit out a reply. Also, fetching the chat history from Twilio takes time as well. Both of which add to the time of the first response.
2. Store chat history per user
The next experiment I did is storing the chat history on the backend instance of the LLM SMS service, and only including the few most recent prompt and responses as the context for the LLM.
I stored the chat history right on the backend instance using Redis to make sure it reads and writes fast. Then I used the standard ChatGPT prompt and response JSON data schema to package the chat history, and only pass the last 3 prompt-response pair to the LLM API as context.
The time-to-first-response for this is much faster than parsing the entire text history to the LLM, and it still gets the conversation context enough to understand follow-up questions.
What’s next
This project excited me a lot because most of it is backend engineering, which I am not very familiar with. I learned how to build robust micro-services that connect with each other (streaming AI response is the micro-service I built), how to ingest a readable stream, and how to build infrastructure for multi-tenancy.
This is useful to expose powerful LLMs like ChatGPT to many parts of the world where the internet is not reliable. But even in places like the US, where the internet is readily available, it can empower businesses that use SMS as their primary contact method to create better chatbot experiences that leverage the power of language generation of LLMs.
While I am putting this project aside for now, I am sure I will pick this back up sometime in the future.